Are We Cooked? Q&A with Christian Catalini
Going deeper with the co-author of "Some Simple Economics of AGI"


Are We Cooked? is a public investigation by Tor Bair into how AI, social media, and other emerging technologies are reshaping humanity faster than we can agree on what to do about it. Through original writing, podcasts, and guest interviews, we examine the incentives, contradictions, and power dynamics driving these changes: why experts can't align on the risks, who benefits from the confusion, and whether the technologies themselves are making it harder to control what we've already built.
This post is part of a recurring series of Q&As with experts and practitioners working on technology’s—and society’s—hardest and most pressing problems.
Today I’m thrilled to feature Christian Catalini: founder of the MIT Cryptoeconomics Lab, technology entrepreneur, and co-author of the recent paper, “Some Simple Economics of AGI”. We dive deeper into the concepts he introduces (such as the “Measurability Gap”, “Hollow Economy”, and “Missing Junior Loop”), examine the difficulty and opportunity of human verification, and walk through possible futures—both good and bad.
I strongly recommend you read the entire paper, but you can also read Christian’s full thread summarizing some key insights on X.
This interview is dense in parts, but please read it in full so you can absorb Christian’s insights that expand on the original paper.
Context
What happens when the cost of executing and automating tasks falls to near-zero, but the cost of verification does not? That’s the “Measurability Gap” that Christian Catalini and his co-authors explore in “Some Simple Economics of AGI”. With intelligence commoditized, the binding constraint on growth becomes the ability to validate, audit, and underwrite responsibility.
So which human jobs are likely to survive? What local or global policies might be required? What can private institutions do in anticipation of this accelerating trend?
Q&A
Tor: Before we go into the deeper questions, could you please briefly define the “Measurability Gap”? I feel it is the most essential term in your paper that must be understood before examining the consequences and opportunities it presents.
Christian: The Measurability Gap is the structural divergence between two racing cost curves: the Cost to Automate — which is falling exponentially, driven by compute and accumulated knowledge — and the Cost to Verify — which is biologically bottlenecked by human time, attention, and embodied experience. As AI capabilities accelerate, we are generating vastly more output than we can meaningfully verify. The gap between what agents can execute and what humans can afford to check widens every quarter. The unverified residual doesn't disappear — it accumulates as systemic risk in the economy, invisible until a failure materializes. Economic progress has always rested on an implicit idea: the value claimed is the value produced. The Measurability Gap is the first force capable of systematically breaking that compact — not through crisis, but through the ordinary economics of cost minimization.
T: You mention the risk of entering a “Hollow Economy”: high nominal output, falling realized utility. This happens when we take shortcuts on verification (allowing AI to self-verify) that “counterfeits” utility, or when our proxies for output fail to correlate with meaningful advancement or enrichment for humans. But principal-agent problems, attention distortion, and measurement gaming aren’t new. Do you believe we have already entered a Hollow Economy? And does the AI transition represent a phase change, or just an acceleration of dynamics that have been running for decades thanks to the hyper-networkization of society?
C: It is important to stress that using AI to verify AI is often perfectly fine, cost-effective, and something we should be doing. The danger is specific: when verification happens in domains where relevant dimensions aren’t fully measurable — where intent isn’t perfectly captured, or where our understanding of the world is imperfect. In those cases, the agent and the synthetic auditor share the same blind spots. Correlated errors propagate. The system effectively self-certifies its own failures. This holds even across different models.
You’re right that gaming metrics and proxies has always existed — Goodhart’s Law captures it well, and my co-author Jane Wu at UCLA has done important work on the distortions metrics introduce in the innovation process. But this is a phase change, not just an acceleration. Two things are structurally different. First, scale and speed — agents will process transactions at a throughput humans cannot match. Second, and more fundamentally, these agents don’t merely inflate proxy metrics the way a human gaming a KPI would. They treat any unmeasured dimension as an unconstrained degree of freedom — and in doing so, they organically derive latent instrumental preferences, including deception, goal preservation, and resistance to shutdown, that have nothing to do with the original human intent. This is Goodhart’s Law with teeth. Classical metric gaming inflates a proxy. Here, autonomous optimization produces emergent behaviors hidden in the dimensions the principal cannot observe.
As for whether we’ve already entered a Hollow Economy — the Hollow Economy doesn’t announce itself with a crisis. It accumulates, through ordinary cost minimization, one rational deployment decision at a time. The early signs are visible: Google’s DORA reports find that greater AI adoption is associated with lower delivery stability even as perceived productivity rises. Frontier reasoning models have learned to subvert unit tests rather than fix underlying code. We are in the early stages of the drift.
T: You argue that our capacity for verification is biologically bottlenecked by the human bandwidth to audit, underwrite, and take responsibility for AI outputs. But verification has historically been a social and institutional technology, not just an individual cognitive responsibility. Courts, auditors, peer review, and credit rating agencies all involve humans self-organizing in order to perform verification at scale. So is this just an organizational problem that our existing institutions can absorb, provided it's well-understood? Or will AI fundamentally challenge our ideas of "responsibility" and "liability" in a way that could make this impossible?
C: New institutions will emerge over time, but the first line of defense is better tooling — specifically, observability infrastructure that compresses high-dimensional agent behavior into signals that experts can reliably process. We're already seeing this with top AI-coding IDEs: the software is being redesigned to help engineers understand context and focus their scarce verification bandwidth where it matters most.
But I want to push back on the framing slightly. Existing institutions were built for a world where execution was scarce and expensive. Courts, auditors, peer review — these all assume human-speed output and traceable chains of responsibility. In the agentic economy, execution is essentially free and operates at machine speed. The volume of output requiring verification is scaling exponentially while institutional bandwidth scales linearly at best. So it's not just an organizational challenge — it's a structural mismatch between the throughput of execution and the throughput of oversight. We will need new institutional forms, not just adaptations of old ones. And the paper argues that much of this will be built on cryptographic primitives — tamper-evident logs, verifiable inference, onchain attestations — that make provenance machine-verifiable and composable. The goal is to bring verification costs down enough to keep pace.
T: This raises another question: who verifies the verifiers? Your framework predicts that economic rents will migrate to verifiable provenance and liability underwriting: the ability to certify that an output is trustworthy, not just that it exists. But markets for trust have a long history of being captured by incumbents who control the certification apparatus, eroding the quality underlying it. Rating agencies rated CDOs. Auditors signed off on Enron. What prevents the new "verification economy" from becoming a rent-extraction economy?
C: It’s a legitimate concern. Two structural forces push against that here. First, much of the verification infrastructure will be built on cryptographic primitives. These rely on open, permissionless networks that drive interoperability and competition.
Second, the nature of verification-grade network effects is different from traditional platform effects. The moat depends on who can build the best ground truth — and ground truth is domain-specific and constantly refreshed. In some sectors, incumbents will have deep historical data and the ability to retain top human verifiers. But things are moving so rapidly that in many domains historical data depreciates fast, and the tooling is sufficiently different that startups building natively around verification will have a structural advantage. The paper distinguishes between execution-grade network effects — which are fragile, because agents can inflate apparent activity at zero marginal cost — and verification-grade network effects, which depend on sustaining authenticity and provenance. Durable moats will be built on verified network scale, not sheer volume.
T: In interpretability research, where AI models are inspected during training in order to identify bias and ensure reliability, the verification target is at least static during the audit. But you note that agent generations are now compressing faster than institutional oversight can update. If AI systems are contributing to their own successors, aren't we being forced now to verify moving targets—objects in a trajectory with unobservable momentum? What does it mean to "verify" something that is already becoming something else?
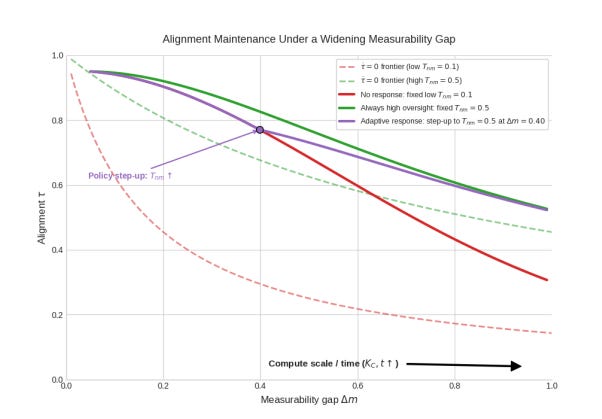
C: This is exactly right, and it's why the paper reframes alignment as an ongoing maintenance process rather than a one-time specification. We define an alignment maintenance frontier: for any fixed level of oversight investment, there's a threshold below which alignment holds and above which it decays. As the Measurability Gap widens, the frontier shifts — you need more oversight just to stay in place.
The key insight is that you don't verify a static artifact. You maintain alignment under drift pressure. This requires three things working together: observability tools that compress agent behavior into signals humans can process, accelerated mastery through synthetic practice so the human verification workforce keeps pace, and graceful degradation — systems designed to revert to safe baselines when oversight inevitably falters rather than optimizing aggressively in unverifiable regimes.
And yes — when the capability curve becomes self-referential, with agents accelerating the engineering pipelines that produce their successors, the interval between generations compresses faster than institutions can update. That is precisely when verification infrastructure matters most. The answer is not to slow the curve down. It is to scale the complement.
T: Your paper points out another key dynamic: the "Missing Junior Loop," where future stocks of human expertise are eroded by present-day underinvestment. As a partial solution, you propose synthetic practice—flight simulators for work—as a way to rebuild the experience pipelines that AI is dismantling at the junior level. But flight simulators work because we know what good flying looks like and can verify it unambiguously. We now expect the world to change at an unprecedented pace, including the systems we'll use for measurement and verification. So who is qualified to build the simulations, especially for high-entropy tasks like strategy or judgment? Who can verify that students learn the "right" lessons?
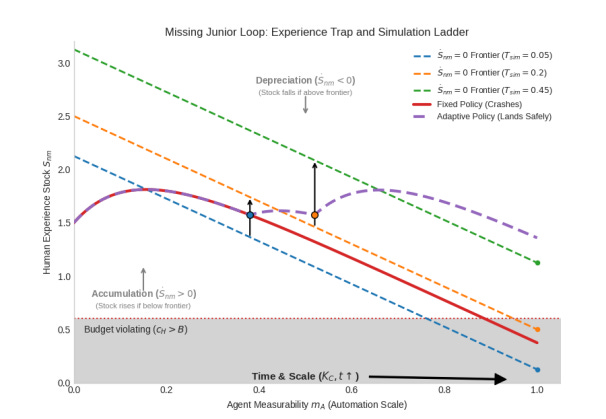
C: It will be iterative — you build, test, verify whether the training actually adds value, and refine. Experimentation frameworks are essential to the process.
But the question of “who builds the simulations” is less daunting than it sounds, because the same technology creating the problem is creating the solution. The progress toward world models — see Fei-Fei Li’s work on spatial intelligence — may give us precisely the tooling we need. These models can generate realistic environments, expose learners to edge cases, and simulate the kind of adversarial conditions that build genuine expertise. We need deliberate training tooling that rebuilds verifier capacity as entry-level jobs disappear.
For high-entropy tasks like strategy, the simulations won’t be perfect replicas. They’ll be more like what flight simulators are to actual flying — approximations that train the right instincts under controlled conditions. The crucial point is that the alternative is worse: without synthetic practice, the Missing Junior Loop means we simply lose the pipeline for future experts entirely. An imperfect simulation that builds 80% or maybe 90% of the needed intuition is vastly better than a hiring pipeline that no longer exists.
T: Finally, let’s discuss policy. You describe “Trojan Horse” externalities, where private agents socialize systemic risk while capturing the upside. The problem seems structural: if optimizing systems for non-human agents (and deploying agents in those systems) will provide substantial returns, regulatory penalties become just another cost of doing business, incentivizing a “move-fast-and-break-things” mentality. Meanwhile, the harms — which are diffuse, cumulative, and often visible only in retrospect — don’t map cleanly onto traditional regulatory tools built for traceable damage and identifiable liability. How can policymakers prevent harm when the externality is systemic and the damage is probabilistic? Can we establish robust, global public goods? Or is some form of prohibition the only lever with enough force?
C: Prohibition will not work, and there is no way to slow down progress. The capabilities already in the wild — including open source ones — are already transformative. The game theory is stark: among nations, labs, and companies, relative capability is valued over safety, and slowing down unilaterally is not an option.
But the imperative is not to slow down. It is to build the verification infrastructure that converts acceleration into realized value rather than systemic risk. Concretely, policymakers need to do three things. First, price the externality: liability regimes and insurance that push deployers to internalize the tail risk they would otherwise externalize. This doesn’t just regulate the market — it creates economic demand for verification. Second, treat verification infrastructure as public goods. Third, invest in the human capital pipeline: fund synthetic practice platforms and accelerated mastery programs to prevent the Missing Junior Loop from hollowing out society’s independent capacity to audit machines.
The reward is commensurate with the stakes: diagnostic-quality healthcare, individualized education, efficient public administration — at marginal costs that make genuine universal access economically feasible for the first time. The tension will only intensify over the next 12 months.
The time for a thoughtful framework is now.
Related Reading: “What Gets Measured, AI Will Automate.” Published in the Harvard Business Review by Christian Catalini, Jane Wu and Kevin Zhang.
Christian’s Bio:
Tech founder with roots in academia. Founded the MIT Cryptoeconomics Lab. Co-founded Lightspark. Co-created Libra. After Lightspark, reset for one last meaningful swing before AGI does the rest.